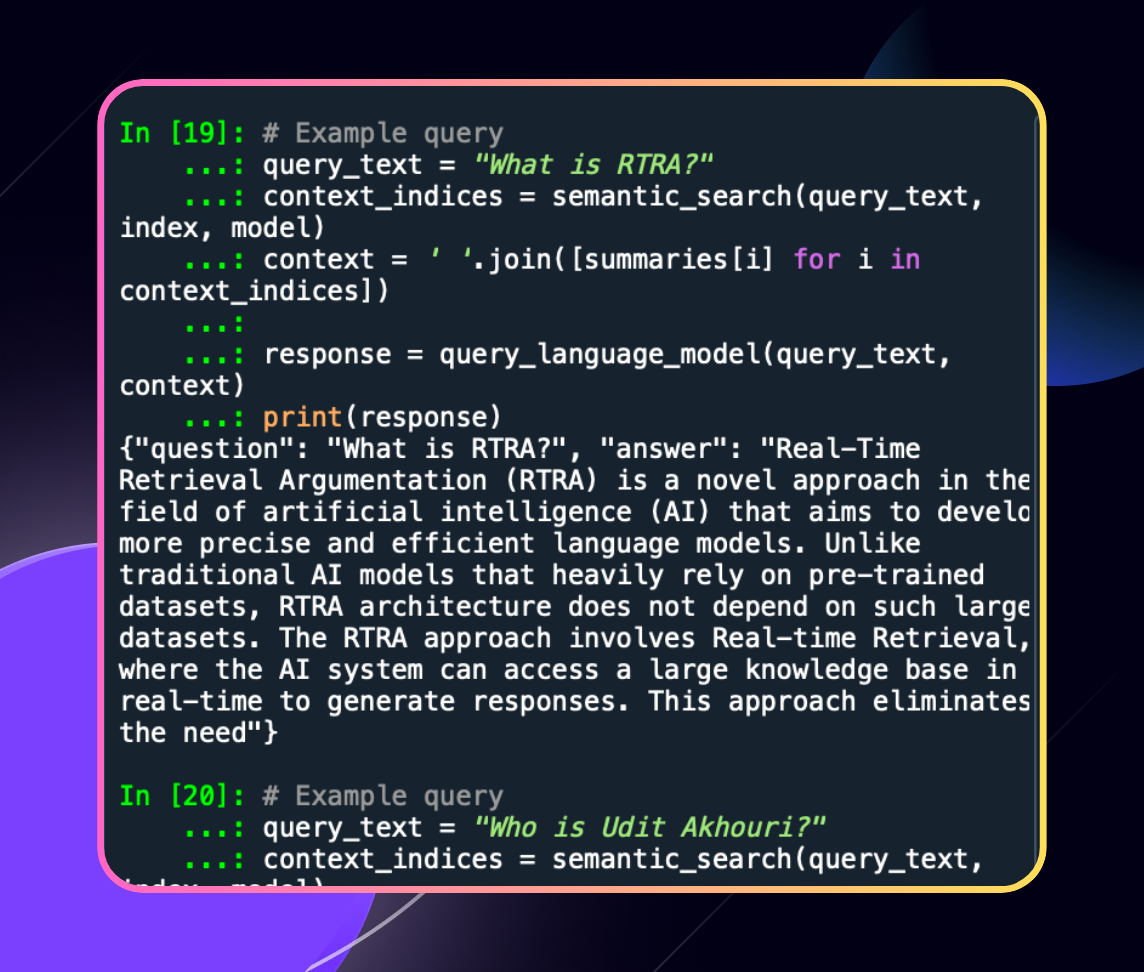
Our focus was to boost retrieval process by eliminating the crawl time of domains. We introduced multiple advanced methods to create a novel approach at building a ML-first web crawler.
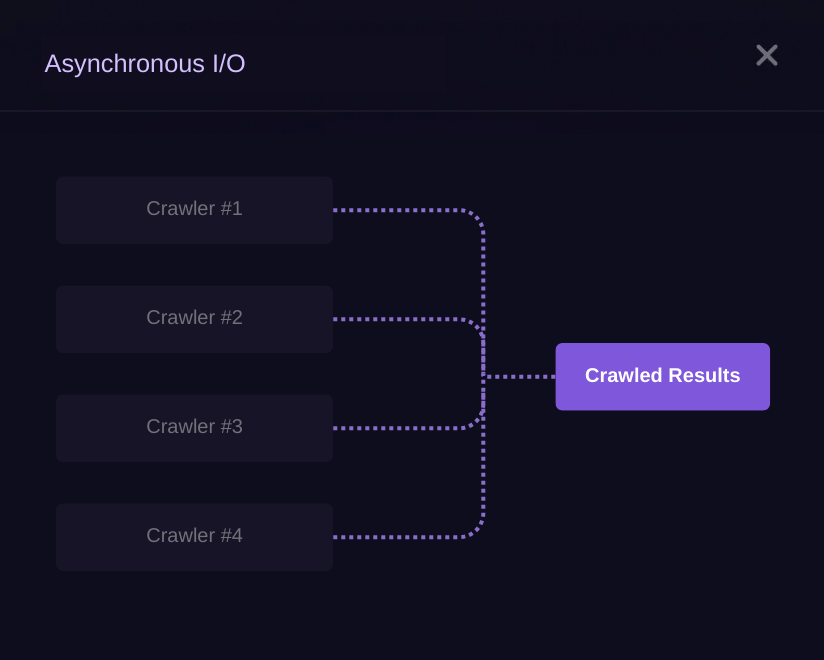
Instead of waiting for each webpage to load one by one (like standing in line at the grocery store), it asks for multiple webpages at the same time (like placing multiple online orders simultaneously). This way, it doesn’t waste time waiting and can move on to other tasks.
02
Data Preprocessing & Merging
By setting a high concurrency, the crawler can handle multiple tasks simultaneously. This speeds up the process compared to handling only a few tasks at a time.
03
Local Embedding Setup
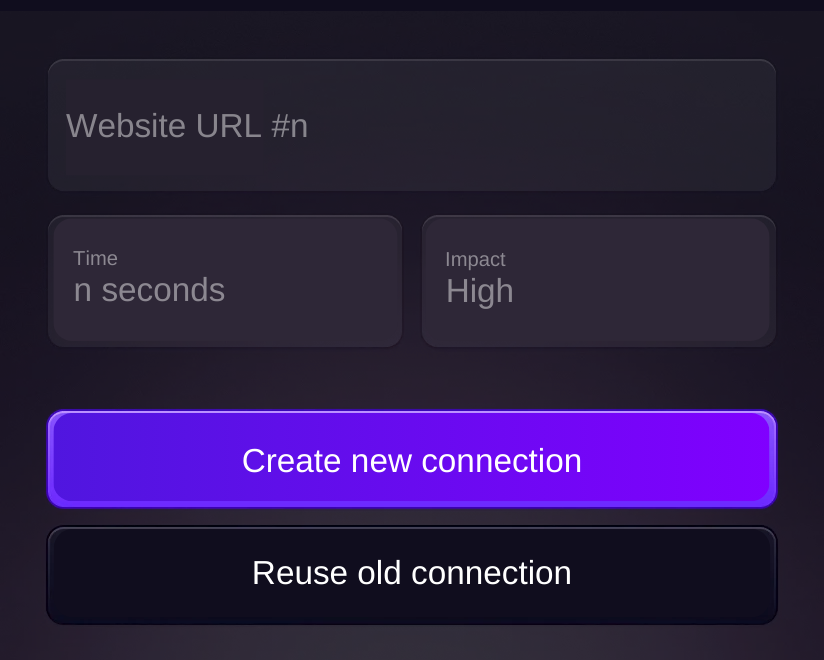
HyperLLM reduces the time and resources needed to open new connections by reusing existing ones. Think of it like reusing a shopping bag instead of getting a new one every time.
04
Dense Vector Semantic Retrieval
By remembering visited URLs, HyperCrawl avoids revisiting and reprocessing the same pages. This prevents wasting time on duplicate work.
05
Historical Dataset Management
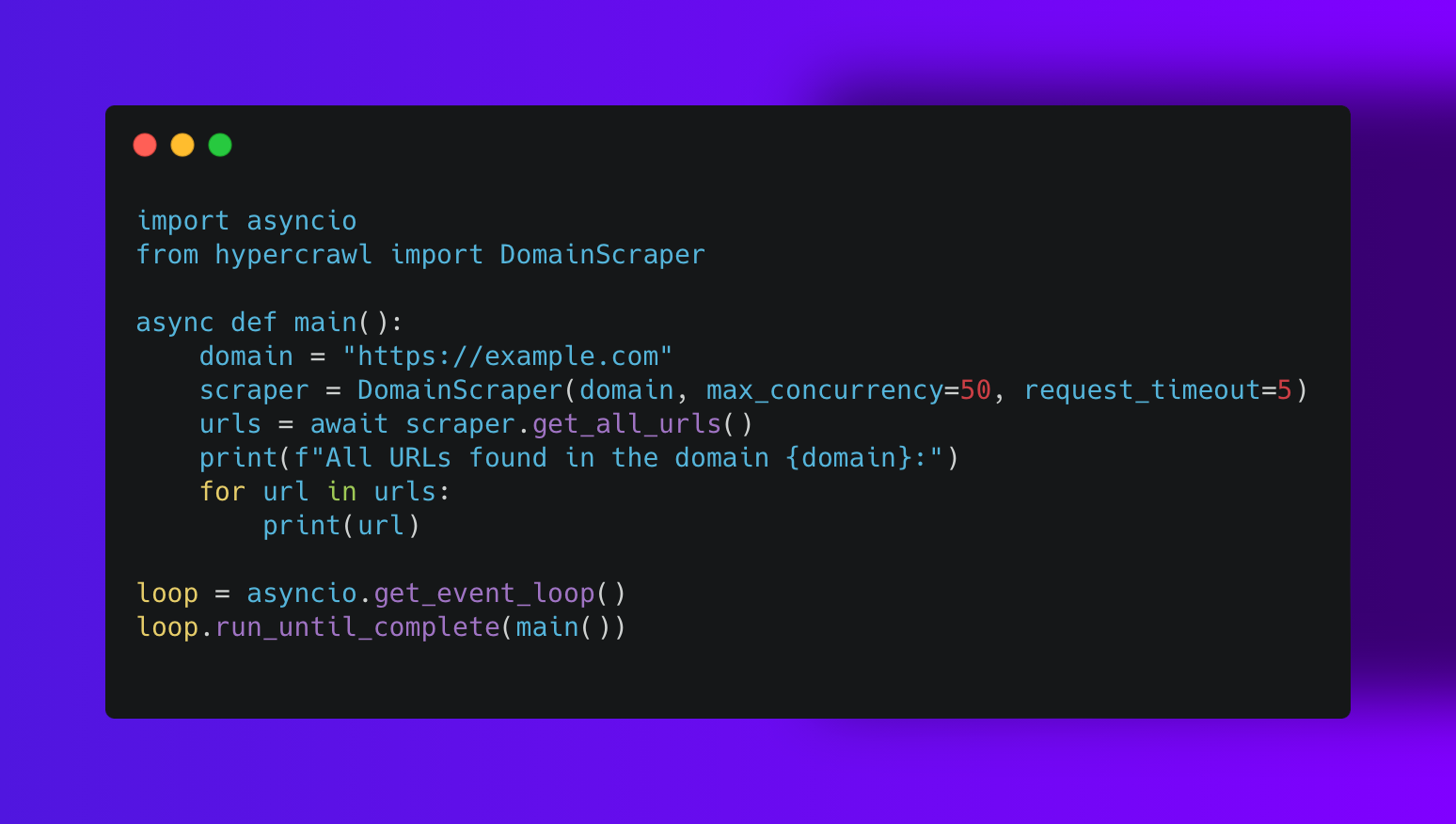
This makes the HyperCrawler versatile and able to run in various environments like Google Colab or Jupyter notebook without running into issues with event loops.
Seamless Dev Journey
Access Exthalpy Anywhere
Use exthalpy via API
Want to use HyperCrawl within web-based & JS projects? HyperCrawl is available there too.
Pip install exthalpy
Install & work with HyperCrawl regardless your core infrastructure.
Go cloud or run locally
HyperCrawl is available on both as an API and as a Python library which is opens-source and free to use.
Pip install Exthalpy
Python Core library
Pip install Hypercrawl
Python Turbo library
Pip install Hypersem
API URL to Call anywhere..
Community
Read best resources to get started..
@golurk
Digital collector & 3D Designer
$3.2M
Total Volume
19
Drops
@golurk
Digital collector & 3D Designer
$3.2M
Total Volume
19
Drops
@golurk
Digital collector & 3D Designer
$3.2M
Total Volume
19
Drops
@golurk
Digital collector & 3D Designer
$3.2M
Total Volume
19
Drops
What's our mission?
We are building the future of fast LLMs.
HyperCrawl is a part of HyperLLM where we are dedicated to build the infrastructure for a world of future LLMs. Models that requires less computational resources & outperforms any models available.